diff --git a/.DS_Store b/.DS_Store
index 19ae14f5e69d2bbbbdb52b8adfc3ef5b1fa26104..eb21c14837cde40829ae51d1b1ab7ef9341a5019 100644
Binary files a/.DS_Store and b/.DS_Store differ
diff --git a/.env b/.env
new file mode 100644
index 0000000000000000000000000000000000000000..2164f16ec8b25eeb881ee54f71e2e49476347efc
--- /dev/null
+++ b/.env
@@ -0,0 +1,4 @@
+DB_HOST=wi-sql.fh-muenster.de
+DB_PORT=5432
+DB_USER=digibim
+DB_PASSWORD='Di&i$IM0815'
diff --git a/04_data_analysis.qmd b/04_data_analysis.qmd
index 199c1ca56c8dffbf9b7d2e8ef9ba77835dbe555b..8dea72a7b39506d3b325cd4c2c7a428757826380 100644
--- a/04_data_analysis.qmd
+++ b/04_data_analysis.qmd
@@ -6,6 +6,50 @@ number-offset: [5,0]
bibliography: references.bib
---
+```{python}
+#| eval: true
+#| echo: false
+#| output: false
+
+import os
+from dotenv import load_dotenv
+import sqlalchemy
+import pandas as pd
+from urllib.parse import quote_plus
+
+load_dotenv(".env")
+
+class Database:
+ def __init__(self, db_name):
+ self.conn = db_connect(db_name)
+
+ def __getattr__(self, table_name):
+ return pd.read_sql_table(table_name, self.conn)
+
+ def list_tables(self):
+ inspector = sqlalchemy.inspect(self.conn)
+ table_names = inspector.get_table_names()
+ return table_names
+
+def db_connect(db_name):
+ hostname=os.getenv("DB_HOST")
+ user=os.getenv("DB_USER")
+ password=quote_plus(os.getenv("DB_PASSWORD"))
+ conn = sqlalchemy.create_engine(f'postgresql+psycopg2://{user}:{password}@{hostname}/{db_name}')
+ return conn
+
+def get_table(db_name, table_name):
+ conn = db_connect(db_name)
+ dat = pd.read_sql_table(table_name, conn)
+ return dat
+
+def get_all_tables(db_name):
+ db_obj = Database(db_name)
+ return db_obj
+
+
+```
+
## Where are we? {.unnumbered}
@@ -258,66 +302,633 @@ df %>% kbl(format = "html", escape = FALSE, col.names = c("","","Explanation","E
```
+# Explorative Data Analysis (EDA) {background-color="#0014a0"}
+
+::: footer
+:::
+
+## Introduction to EDA
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+#### EDA is an iterative process:
+
+1. Generate questions about your data.
+2. Search for answers by visualising, transforming, and modelling your data.
+3. Use what you learn to refine your questions and/or generate new questions.
+
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+#### EDA is a state of mind:
+
+- EDA is not a formal process with a strict set of rules
+- During the initial phases of EDA you should feel free to investigate every idea that occurs to you
+- Some of these ideas will pan out, and some will be dead ends
+- As your exploration continues, you will home in on a few particularly productive areas that you’ll eventually write up and communicate to others
+:::
+::::
+
+
+
+## Definitions
-# Key figures {background-color="#0014a0"}
+- A **variable** is a quantity, quality, or property that you can measure.
+
+- A **value** is the state of a variable when you measure it. The value of a variable may change from measurement to measurement.
+
+- An **observation** is a set of measurements made under similar conditions (you usually make all of the measurements in an observation at the same time and on the same object). An observation will contain several values, each associated with a different variable. I’ll sometimes refer to an observation as a data point.
+
+- **Tabular data** is a set of values, each associated with a variable and an observation. Tabular data is tidy if each value is placed in its own “cellâ€, each variable in its own column, and each observation in its own row.
+
+
+# Tidy data {background-color="#0014a0"}
::: footer
:::
-## Averages
+## Tidy data
-## Variation
+Starting point for any data analysis should be a tidy dataset. You can represent the same underlying data in multiple ways. There are three interrelated rules which make a dataset tidy:
-## Ratios
+1. Each variable must have its own column.
+2. Each observation must have its own row.
+3. Each value must have its own cell.
-## Dependencies/relationships
+{#fig-tidy}
-## Correlation
-## Non-linear relationships
-## Contingency
+## Making data tidy
-## Difference-in-Differences
+:::: {.columns}
-## Causality
+::: {.column width="47.5%"}
-# Best practices {background-color="#0014a0"}
+{#fig-tidy1}
+:::
+::: {.column width="5%"}
-## Feature Engineering
+:::
+::: {.column width="47.5%"}
+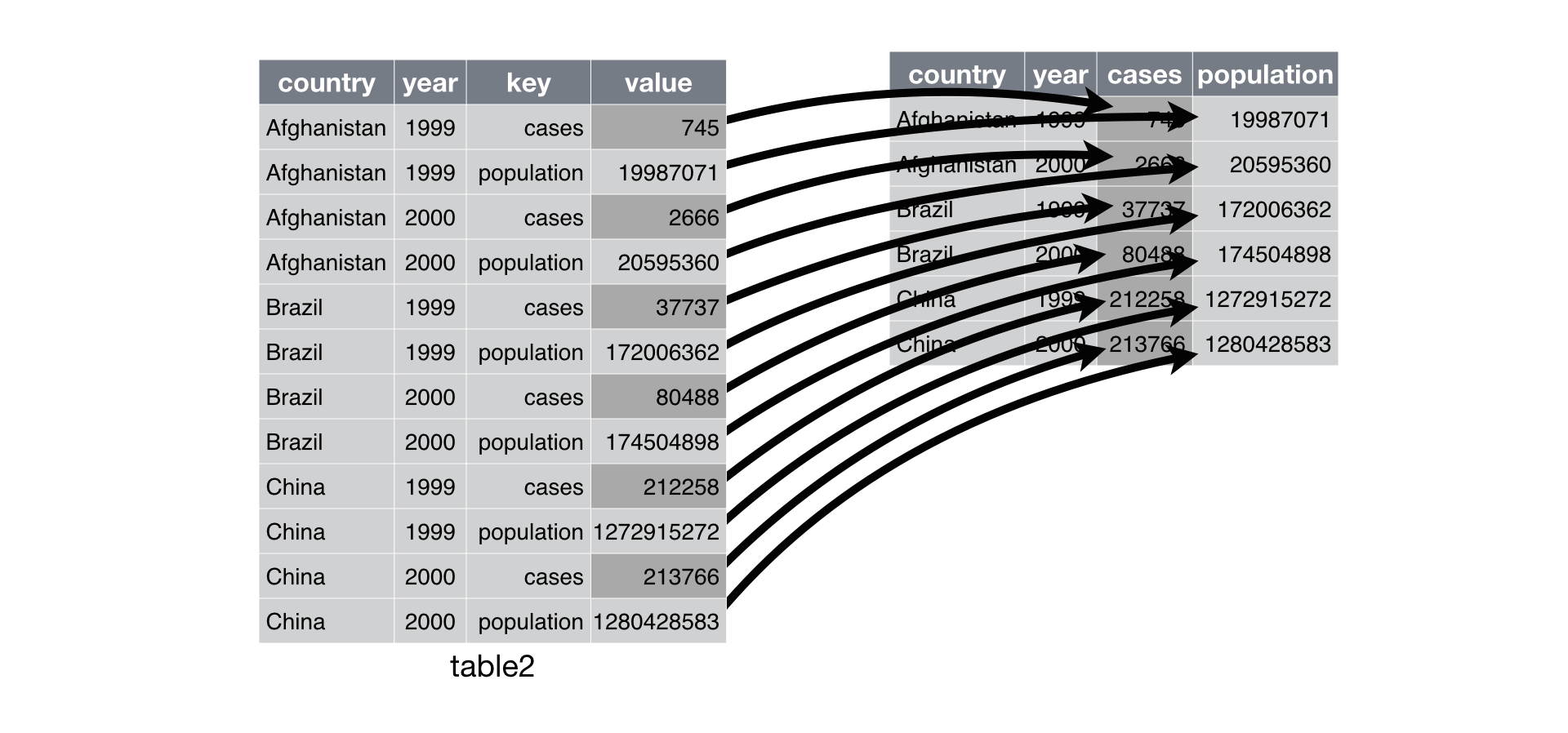{#fig-tidy2}
-## Data preparation
+:::
+::::
-{#fig-dataprep}
-{#fig-featureengineering}
+## Describe tables with pandas
+
+:::: {.columns}
+::: {.column width="37.5%"}
+- In order to get an overview on a table, you can use the `describe` method
+- By default, describe computes 7 summary figures for numeric columns (mean, standard deviation, min, max and quartiles)
+- The argument `include='all'` adds an overview on categorical variables
+
+
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="57.5%"}
+
+#### Example: DVD Rental
+
+```{python}
+#| echo: true
+#| cache: true
+
+# Import tables
+import pandas as pd
+dvdrental = get_all_tables("dvdrental")
+dvdrental.list_tables()
+```
+
+
+```{python}
+#| echo: true
+#| cache: true
+
+# Describe customer table
+dvdrental.customer.describe(include='all')
+```
+
+:::
+::::
+
+
+## Merge/join tables with pandas
+
+
+- To join two tables, the `merge` method from Python's pandas library can be used:
+- **Syntax & Parameters:**
+ - `pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, ...)`
+ - `left`: First DataFrame to join.
+ - `right`: Second DataFrame to join.
+ - `how`: Type of merge to perform (e.g., 'inner', 'outer', 'left', 'right').
+ - `on`: Column name(s) to join on. Must be found in both DataFrames.
+ - `left_on`: Column(s) from the left DataFrame to use as keys.
+ - `right_on`: Column(s) from the right DataFrame to use as keys.
+- **Join Types:**
+ - `inner`: Only rows with matching keys in both DataFrames are included.
+ - `outer`: All rows from both DataFrames are included, with NaN for missing keys.
+ - `left`: All rows from the left DataFrame are included, along with matched rows from the right DataFrame.
+ - `right`: All rows from the right DataFrame are included, along with matched rows from the left DataFrame.
+
+
+## Example: Merge/join tables with pandas
+
+```{python}
+#| echo: true
+#| cache: true
+
+# Merge customer, rental and payment tables
+df = (
+dvdrental.customer.merge(
+ dvdrental.rental,
+ on = ['customer_id']
+).merge(
+ dvdrental.payment,
+ on = ['rental_id', 'customer_id']
+)
+)
+
+df.describe(include='all')
+```
+
+
+## Aggregate tables with pandas
+
+
+- In pandas, the `agg` function is used for aggregation operations, allowing for multiple statistics to be calculated simultaneously.
+
+- **Syntax & Parameters:**
+ - `DataFrame.agg(func, axis=0, *args, **kwargs)`
+ - `func`: Function, string function name, list of functions, or dict of column names to functions.
+ - `axis`: Axis along which the function is applied (0 for columns, 1 for rows).
+
+- **Function Input Varieties:**
+ - Single function (e.g., `'sum'`)
+ - List of functions (e.g., `['sum', 'mean']`)
+ - Dictionary mapping columns to functions (e.g., `{'col1': 'sum', 'col2': ['mean', 'std']}`)
+
+- **Behavior with GroupBy:**
+ - Often used in conjunction with `groupby` to perform grouped aggregations.
+
+
+## Example: Aggregate tables with pandas
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+```{python}
+#| echo: true
+#| cache: true
+
+# Merge rental, film and actor
+df = (
+dvdrental.rental
+.merge(dvdrental.inventory, on = ['inventory_id'])
+.merge(dvdrental.film, on = ['film_id'])
+.merge(dvdrental.film_actor, on = ['film_id'])
+.merge(dvdrental.actor, on = ['actor_id'])
+)
+```
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+```{python}
+#| echo: true
+#| cache: true
+
+# Count rentals per actor
+(
+ df
+ .groupby(by = ['actor_id', 'last_name', 'first_name'],
+ as_index = False)
+ .agg(count_rentals=('rental_id', 'count'))
+ .sort_values(by = 'count_rentals', ascending=False)
+)
+```
+:::
+::::
+
+
+
+
+# Variation {background-color="#0014a0"}
::: footer
:::
+## Variation
+
+- **Variation Definition:** Tendency of variable values to change with each measurement.
+- **Continuous Variables:** Each measurement likely yields slightly different results.
+- **Constant Quantities:** Even with constants like the speed of light, measurements vary due to errors.
+- **Categorical Variables Variation:**
+ - Different subjects, e.g., various people's eye colors.
+ - Different times, e.g., an electron's energy levels at varied moments.
+- **Pattern of Variation:** Each variable has a unique pattern that can provide insightful information.
+- **Understanding Patterns:** Visualizing a variable's distribution helps understand its variation pattern.
+
+
+## Histograms
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+
+
+- A **histogram** visualizes the distribution of continuous variables
+- A bar for each bin represents the frequency of observations in this bin
+- Bins can be specified in different variants (e.g. same width vs. varying width)
+
+```{python}
+#| eval: true
+#| echo: true
+#| cache: true
+
+# Compute revenue per customer
+df = (
+dvdrental.customer
+.merge(dvdrental.rental, on = ['customer_id'])
+.merge(dvdrental.payment, on = ['rental_id', 'customer_id'])
+.groupby('customer_id')
+.agg(revenue=('amount', 'sum'))
+)
+```
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+The `matplotlib` library offers a function `hist` to draw histograms:
-## Definition
+```{python}
+#| eval: true
+#| echo: true
+#| label: fig-hist
+#| fig-cap: "Histogram of revenues per cusotmer in the DVD Rental data base"
+#| cache: true
+
+import matplotlib.pyplot as plt
+plt.hist(df['revenue'], bins = 10)
+plt.show()
+```
+:::
+::::
-# Exercise {background-color="#0014a0"}
-## Exercise
-::: callout-caution
-## Exercise
-Please analyze the following use case
+## Bar plots
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+
+- In a *bar plot*, the height of a bar represents the frequency of values of a categorical variable
+- Bars can show absolute or relative frequencies
+
+```{python}
+#| eval: true
+#| echo: true
+#| cache: true
+
+# Compute rentals per staff member
+df = (
+dvdrental.customer
+.merge(dvdrental.rental, on = ['customer_id'],
+ suffixes = ('_customer', '_rental'))
+.merge(dvdrental.staff, on = ['staff_id'],
+ suffixes = ('_customer', '_staff'))
+.groupby(['staff_id', 'first_name_staff',
+ 'last_name_staff', 'email_staff'],
+ as_index=False)
+.agg(rentals_count=('rental_id', 'count'))
+)
+```
+:::
+
+::: {.column width="5%"}
:::
+::: {.column width="47.5%"}
+
+The `matplotlib` library offers a function `bar` to draw histograms:
+```{python}
+#| eval: true
+#| echo: true
+#| label: fig-bar
+#| fig-cap: "Barplot of count of rentals per staff member in the DVD Rental data base"
+#| cache: true
+
+plt.bar(df['first_name_staff'], df['rentals_count'])
+plt.show()
+```
+:::
+::::
+
+
+
+## Analyzing variation/distributions
+
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+#### Questions to ask:
+
+1. Which values are the most common? Why?
+2. Which values are rare? Why? Does that match your expectations?
+3. Can you see any unusual patterns? What might explain them?
+
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+#### KPIs describing the distribution:
+
+- Frequencies (absolute, relative)
+- Average
+- Standard Deviation, Variance, Median Absolute Deviation
+- Skewness, Kurtosis
+- Outliers
+:::
+::::
+
+
+
+
+
+# Covaration {background-color="#0014a0"}
+
+## Covariation
+
+- **Variation:** describes the behavior within a variable
+- **Covariation:** describes the behavior between variables
+- Covariation is the tendency for the values of two or more variables to vary together in a related way
+- The best way to spot covariation is to visualise the relationship between two or more variables
+- How you do that should again depend on the **type** of variables involved.
+
+## Covariation of a cagtegorical and a continuous variable (1/2)
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+
+- A *bar plot* can be used to compare aggregated values of a numeric values across categories from another variable
+- Aggregations can be counts, sums, ...
+
+```{python}
+#| eval: true
+#| echo: true
+#| cache: true
+
+# Compute rentals per staff member
+df = (
+dvdrental.customer
+.merge(dvdrental.rental, on = ['customer_id'])
+.merge(dvdrental.payment, on = ['customer_id','rental_id', 'staff_id'])
+.merge(dvdrental.staff, on = ['staff_id'], suffixes = ('_customer','_staff'))
+.groupby(['staff_id', 'first_name_staff',
+ 'last_name_staff', 'email_staff'],
+ as_index=False)
+.agg(revenue=('amount', 'sum'))
+)
+```
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+
+
+```{python}
+#| eval: true
+#| echo: true
+#| label: fig-covarbars
+#| fig-cap: "Barplot of count of rentals per staff member in the DVD Rental data base"
+#| cache: true
+
+plt.bar(df['first_name_staff'], df['revenue'])
+plt.show()
+```
+:::
+::::
+
+
+
+## Covariation of a cagtegorical and a continuous variable (2/2)
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+
+- Using **boxplots**, the entire distribution of a continuous variable can be compared across categories of another variable
+
+```{python}
+#| eval: true
+#| echo: true
+#| cache: true
+
+# Merge tables for revenues
+df = (
+dvdrental.customer
+.merge(dvdrental.rental, on = ['customer_id'],
+ suffixes = ('_customer', '_rental'))
+.merge(dvdrental.payment, on = ['customer_id',
+ 'rental_id',
+ 'staff_id'],
+ suffixes = ('_customer', '_rental'))
+.merge(dvdrental.staff, on = ['staff_id'],
+ suffixes = ('_customer', '_staff'))
+)[['first_name_staff', 'amount']]
+```
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+
+The `seaborn` library offers a function `sns.boxplot` to easily draw multiple boxplots for comparison:
+```{python}
+#| eval: true
+#| echo: true
+#| label: fig-boxs
+#| fig-cap: "Boxplots of revenues per rental separately by staff members"
+#| cache: true
+
+import seaborn as sns
+sns.boxplot(x = 'first_name_staff', y = 'amount', data = df)
+```
+:::
+::::
+
+## Covariation of two cagtegorical variables
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+Create a table to identify the number of rentals per film category and country:
+
+```{python}
+df = (
+dvdrental.film
+.merge(dvdrental.inventory, on = ['film_id'])
+.merge(dvdrental.store, on = ['store_id'])
+.merge(dvdrental.rental, on = ['inventory_id'])
+.merge(dvdrental.film_category, on = ['film_id'])
+.merge(dvdrental.category, on = ['category_id'])
+.merge(dvdrental.address, on = ['address_id'])
+.merge(dvdrental.city, on = ['city_id'])
+.merge(dvdrental.country, on = ['country_id'])
+.groupby(['country', 'name'],
+ as_index=False)
+.agg(count = ('rental_id', 'count'))
+)
+df
+```
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+
+The `seaborn` library offers a function `heatmap` to create heatmaps:
+```{python}
+#| eval: true
+#| echo: true
+#| label: fig-heatmap
+#| fig-cap: "Heatmap for rentals across film categories and countries"
+#| cache: true
+
+df_pivot = df.pivot(index="name", columns="country", values="count")
+sns.heatmap(df_pivot)
+```
+:::
+::::
+
+
+## Covariation of two continuous variables
+
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+Create a table with duration and amount paid
+
+```{python}
+df = (
+dvdrental.rental
+.merge(dvdrental.payment, on = ['rental_id', 'customer_id', 'staff_id'])
+)
+df['duration'] = (dvdrental.rental.return_date - dvdrental.rental.rental_date).dt.total_seconds()/60/60/24
+df[['rental_id', 'duration', 'amount']]
+
+```
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+
+The `pandas` library offers a method `plot.scatter` to create scatterplots:
+```{python}
+#| eval: true
+#| echo: true
+#| label: fig-scatter
+#| fig-cap: "Scatterplot for rental duration and amount paid"
+#| cache: true
+
+df.plot.scatter(x = 'duration', y = 'amount')
+
+```
+:::
+::::
+
+
+## Analyzing covariation/relationships/dependencies
+
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+#### Questions to ask:
+
+1. Which variables show common patterns? Are they reasonable/explainable?
+2. What form does the relationship have: is it linear, non-linear?
+
+
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+#### KPIs describing the distribution:
+
+- Correlaion (Pearson, Spearman, Kendall)
+- Contingency ($\chi^2$, Cramérs $V$)
+- ...
+:::
+::::
+
+
+
+
+
+## Looking back: Data preparation
+
+{#fig-dataprep}
+
+## Feature engineering
+
+{#fig-featureengineering}
+
+
+
+::: footer
+:::
+
+
+
# References {.unnumbered .scrollable}
diff --git a/04_data_analysis_cache/revealjs/__packages b/04_data_analysis_cache/revealjs/__packages
new file mode 100644
index 0000000000000000000000000000000000000000..630f1cc0301a4e19649bf7b6aeb20c7e6668f191
--- /dev/null
+++ b/04_data_analysis_cache/revealjs/__packages
@@ -0,0 +1,3 @@
+kableExtra
+tibble
+magrittr
diff --git a/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.RData b/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.RData
new file mode 100644
index 0000000000000000000000000000000000000000..689b29e9b68ef3c6e36d1792daf7857d51c8ccb9
Binary files /dev/null and b/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.RData differ
diff --git a/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.rdb b/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.rdx b/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/fig-bar_fc1ff52eda35eb054746db6a36567957.rdx differ
diff --git a/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.RData b/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.RData
new file mode 100644
index 0000000000000000000000000000000000000000..a22f782eec9f213835e94486fc796d1d6100db7b
Binary files /dev/null and b/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.RData differ
diff --git a/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.rdb b/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.rdx b/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/fig-boxs_3f8cf81cf2682465091dca4869905d5b.rdx differ
diff --git a/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.RData b/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.RData
new file mode 100644
index 0000000000000000000000000000000000000000..3a1f1d4ccb5f96919e43605763e1340f699f1f14
Binary files /dev/null and b/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.RData differ
diff --git a/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.rdb b/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.rdx b/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/fig-hist_71caef5da26f2f509bcda560d69b149f.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.RData
new file mode 100644
index 0000000000000000000000000000000000000000..95e94496fc5c5e7a31a6d5cb1ca42b2460db195c
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-10_479bbfcec8812b71d6fc6e530e31e965.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.RData
new file mode 100644
index 0000000000000000000000000000000000000000..1d000f26a385e5c98b57f31e50085f5d38d35007
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-11_89441b0133c42598b635a86797c59c6a.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.RData
new file mode 100644
index 0000000000000000000000000000000000000000..093df72a3629fe8080be43acd89c1d5815c72d00
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-12_687914cfbaeeeeec53a7c7fefae3bd0b.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.RData
new file mode 100644
index 0000000000000000000000000000000000000000..7e24d41ca918f1fdd9fdeaa601c2841964a2efb8
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-14_35e622235d58d5353508a610142fbead.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.RData
new file mode 100644
index 0000000000000000000000000000000000000000..596e8b2a0294134538b03151640a0cb3fc57f2a6
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-16_4931e7a3e18bdabe5cfeb1ed50042ee4.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.RData
new file mode 100644
index 0000000000000000000000000000000000000000..1e09bd36c79ef6990d3e5c08f35d3be0225fc26d
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-18_80ed6c4419c76e7380fd983d0a842026.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.RData
new file mode 100644
index 0000000000000000000000000000000000000000..0bd08a713151f2f867a593cf0a3bd85e4f4bf141
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-19_7fead5d28eb0b764e98a71e5b5c9ee90.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.RData
new file mode 100644
index 0000000000000000000000000000000000000000..4800e39c996e300747f43f322a8ec73037833273
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-1_35d11017ccc01a8441741046e75685cc.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.RData
new file mode 100644
index 0000000000000000000000000000000000000000..1467ab02f95d4720a471e74ba26d31826f9d715d
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-20_314d5ec78f5adc406f836667b39eb11b.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.RData
new file mode 100644
index 0000000000000000000000000000000000000000..26b0031818ce2ad4832e70fdc69d6c6e124bc005
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..a24957bca9c14578ac88e89a5c5ce011f3cb015b
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.rdb differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..7a69961defc6abae6d82232aecef5060c0974c18
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-2_6b7bb75b52acd1927a1783d2a3030a3b.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.RData
new file mode 100644
index 0000000000000000000000000000000000000000..98ddd9c208bc13e30079b6a60bf6e8d4f48c2de1
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e11fc7487c71ecddfbcf62834ffa3cd98da2cb59
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.rdb differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..5fc456d438f75329bfbacd760e0378b667d359e2
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-3_6117d9d1ce684bfd1f7d17dc35b7188c.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.RData
new file mode 100644
index 0000000000000000000000000000000000000000..7eaca0984ed3ab7c70aee2efd0fbe058244706b3
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..5529c92159b0c080602e230d12e0d88f3cc851d6
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.rdb differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..f79a758f8ebcaad073f4db70e73fef86bb3a604e
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-4_e098d7dbb269d0b3dd75b7171646472c.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.RData
new file mode 100644
index 0000000000000000000000000000000000000000..7747d9041e536d93d3609f23b381837f5f07d41d
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..5529c92159b0c080602e230d12e0d88f3cc851d6
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.rdb differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..cfa5c269e5b6317cc9d1ac12a378c742b7a6fa2a
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-5_2d0a40b600e80a7cafe8427cf2d9c1ea.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.RData
new file mode 100644
index 0000000000000000000000000000000000000000..e7195ce05772e9948d1ea164b5fe905a80b2dcd1
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..40511247a8e749ceab87ad04ceba557aa83f6376
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.rdb differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..35751a4d3fcd5be491597caae077a64ee8637e4e
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-6_eb907bfe5d5b24818e0038af41345d93.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.RData
new file mode 100644
index 0000000000000000000000000000000000000000..f41ad6e7281ef28b61235143bdec838c28657170
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-7_4157d48af9e03dcccf842a5b8b44284a.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.RData
new file mode 100644
index 0000000000000000000000000000000000000000..dabebf36884913c278042d40a2fd21750793aa0c
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-8_c3b521478ddf338ea9816a5de15b5cd8.rdx differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.RData b/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.RData
new file mode 100644
index 0000000000000000000000000000000000000000..f306f887f8680baa14d3f763b7a7c8c4edd4b3ae
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.RData differ
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.rdb b/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.rdb
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.rdx b/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.rdx
new file mode 100644
index 0000000000000000000000000000000000000000..6fb2189cdb34fa855ea59f3a45e4361c34e897f5
Binary files /dev/null and b/04_data_analysis_cache/revealjs/unnamed-chunk-9_1e14a1e5fdcac4f57383a7cad0b5ef35.rdx differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-bar-3.png b/04_data_analysis_files/figure-revealjs/fig-bar-3.png
new file mode 100644
index 0000000000000000000000000000000000000000..74f428ba1b3983c4854d3115a16ddb773c1d92b2
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-bar-3.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-bar-5.png b/04_data_analysis_files/figure-revealjs/fig-bar-5.png
new file mode 100644
index 0000000000000000000000000000000000000000..74f428ba1b3983c4854d3115a16ddb773c1d92b2
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-bar-5.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-boxs-3.png b/04_data_analysis_files/figure-revealjs/fig-boxs-3.png
new file mode 100644
index 0000000000000000000000000000000000000000..4b8fde2d151be5b30e4d2803a304ba0def0d2914
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-boxs-3.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-boxs-7.png b/04_data_analysis_files/figure-revealjs/fig-boxs-7.png
new file mode 100644
index 0000000000000000000000000000000000000000..4b8fde2d151be5b30e4d2803a304ba0def0d2914
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-boxs-7.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-covarbars-5.png b/04_data_analysis_files/figure-revealjs/fig-covarbars-5.png
new file mode 100644
index 0000000000000000000000000000000000000000..eaecd87b18e6a6b62d1cac6bb2232b569511b642
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-covarbars-5.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-heatmap-9.png b/04_data_analysis_files/figure-revealjs/fig-heatmap-9.png
new file mode 100644
index 0000000000000000000000000000000000000000..23fbfa8a33aa00811331d35f804a2526905f7aa3
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-heatmap-9.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-hist-1.png b/04_data_analysis_files/figure-revealjs/fig-hist-1.png
new file mode 100644
index 0000000000000000000000000000000000000000..4d396c98a31acdb4bddf2cc161a54648d46feacb
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-hist-1.png differ
diff --git a/04_data_analysis_files/figure-revealjs/fig-scatter-11.png b/04_data_analysis_files/figure-revealjs/fig-scatter-11.png
new file mode 100644
index 0000000000000000000000000000000000000000..665e4c669e8fe688b34f92199a9e3e5b08d52997
Binary files /dev/null and b/04_data_analysis_files/figure-revealjs/fig-scatter-11.png differ
diff --git a/05_data_fellacies.qmd b/05_data_fellacies.qmd
index fb325a8306976dbb4d7260587d96f77aa64e4746..04c8bb4db94ebec59d9186342228cd3379f74070 100644
--- a/05_data_fellacies.qmd
+++ b/05_data_fellacies.qmd
@@ -1,6 +1,6 @@
---
title: "Data Literacy"
-subtitle: "Chapter 6: Data Storytelling"
+subtitle: "Chapter 5: Data Fellacies"
author: Prof. Dr. Michael Bücker
number-offset: [6,0]
bibliography: references.bib
@@ -11,11 +11,11 @@ bibliography: references.bib
## Where are we? {.unnumbered}
-
+
-# Data storytelling {background-color="#0014a0"}
+# Data fellacies {background-color="#0014a0"}
::: footer
:::
@@ -31,6 +31,56 @@ bibliography: references.bib
:::
+## Survivorship bias
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+)](img/fellacies_survivorshipbias.png){#fig-survivorshipbias}
+
+:::
+::::
+
+
+
+## False causality
+
+:::: {.columns}
+
+::: {.column width="47.5%"}
+[https://www.tylervigen.com/spurious-correlations](https://www.tylervigen.com/spurious-correlations)
+:::
+
+::: {.column width="5%"}
+
+:::
+
+::: {.column width="47.5%"}
+)](img/fellacies_falsecausality.png){#fig-falsecausality}
+
+:::
+::::
+
+
+
+## Exercise
+
+::: callout-caution
+## Exercise
+
+Please analyze the following use case
+
+
+
+:::
# References {.unnumbered .scrollable}
diff --git a/06_data_storytelling.qmd b/06_data_storytelling.qmd
index 04c8bb4db94ebec59d9186342228cd3379f74070..fb325a8306976dbb4d7260587d96f77aa64e4746 100644
--- a/06_data_storytelling.qmd
+++ b/06_data_storytelling.qmd
@@ -1,6 +1,6 @@
---
title: "Data Literacy"
-subtitle: "Chapter 5: Data Fellacies"
+subtitle: "Chapter 6: Data Storytelling"
author: Prof. Dr. Michael Bücker
number-offset: [6,0]
bibliography: references.bib
@@ -11,11 +11,11 @@ bibliography: references.bib
## Where are we? {.unnumbered}
-
+
-# Data fellacies {background-color="#0014a0"}
+# Data storytelling {background-color="#0014a0"}
::: footer
:::
@@ -31,56 +31,6 @@ bibliography: references.bib
:::
-## Survivorship bias
-
-:::: {.columns}
-
-::: {.column width="47.5%"}
-
-:::
-
-::: {.column width="5%"}
-
-:::
-
-::: {.column width="47.5%"}
-)](img/fellacies_survivorshipbias.png){#fig-survivorshipbias}
-
-:::
-::::
-
-
-
-## False causality
-
-:::: {.columns}
-
-::: {.column width="47.5%"}
-[https://www.tylervigen.com/spurious-correlations](https://www.tylervigen.com/spurious-correlations)
-:::
-
-::: {.column width="5%"}
-
-:::
-
-::: {.column width="47.5%"}
-)](img/fellacies_falsecausality.png){#fig-falsecausality}
-
-:::
-::::
-
-
-
-## Exercise
-
-::: callout-caution
-## Exercise
-
-Please analyze the following use case
-
-
-
-:::
# References {.unnumbered .scrollable}
diff --git a/output/04_data_analysis.html b/output/04_data_analysis.html
index b08f7bebd4f4b615c55056630e4a1866580f8653..f4e3358e8aa30951cc7a99d727f444580fd5fe46 100644
--- a/output/04_data_analysis.html
+++ b/output/04_data_analysis.html
@@ -29,6 +29,71 @@
margin: 0 0.8em 0.2em -1em; /* quarto-specific, see https://github.com/quarto-dev/quarto-cli/issues/4556 */
vertical-align: middle;
}
+ /* CSS for syntax highlighting */
+ pre > code.sourceCode { white-space: pre; position: relative; }
+ pre > code.sourceCode > span { display: inline-block; line-height: 1.25; }
+ pre > code.sourceCode > span:empty { height: 1.2em; }
+ .sourceCode { overflow: visible; }
+ code.sourceCode > span { color: inherit; text-decoration: inherit; }
+ div.sourceCode { margin: 1em 0; }
+ pre.sourceCode { margin: 0; }
+ @media screen {
+ div.sourceCode { overflow: auto; }
+ }
+ @media print {
+ pre > code.sourceCode { white-space: pre-wrap; }
+ pre > code.sourceCode > span { text-indent: -5em; padding-left: 5em; }
+ }
+ pre.numberSource code
+ { counter-reset: source-line 0; }
+ pre.numberSource code > span
+ { position: relative; left: -4em; counter-increment: source-line; }
+ pre.numberSource code > span > a:first-child::before
+ { content: counter(source-line);
+ position: relative; left: -1em; text-align: right; vertical-align: baseline;
+ border: none; display: inline-block;
+ -webkit-touch-callout: none; -webkit-user-select: none;
+ -khtml-user-select: none; -moz-user-select: none;
+ -ms-user-select: none; user-select: none;
+ padding: 0 4px; width: 4em;
+ color: #aaaaaa;
+ }
+ pre.numberSource { margin-left: 3em; border-left: 1px solid #aaaaaa; padding-left: 4px; }
+ div.sourceCode
+ { color: #003b4f; background-color: #f1f3f5; }
+ @media screen {
+ pre > code.sourceCode > span > a:first-child::before { text-decoration: underline; }
+ }
+ code span { color: #003b4f; } /* Normal */
+ code span.al { color: #ad0000; } /* Alert */
+ code span.an { color: #5e5e5e; } /* Annotation */
+ code span.at { color: #657422; } /* Attribute */
+ code span.bn { color: #ad0000; } /* BaseN */
+ code span.bu { } /* BuiltIn */
+ code span.cf { color: #003b4f; } /* ControlFlow */
+ code span.ch { color: #20794d; } /* Char */
+ code span.cn { color: #8f5902; } /* Constant */
+ code span.co { color: #5e5e5e; } /* Comment */
+ code span.cv { color: #5e5e5e; font-style: italic; } /* CommentVar */
+ code span.do { color: #5e5e5e; font-style: italic; } /* Documentation */
+ code span.dt { color: #ad0000; } /* DataType */
+ code span.dv { color: #ad0000; } /* DecVal */
+ code span.er { color: #ad0000; } /* Error */
+ code span.ex { } /* Extension */
+ code span.fl { color: #ad0000; } /* Float */
+ code span.fu { color: #4758ab; } /* Function */
+ code span.im { color: #00769e; } /* Import */
+ code span.in { color: #5e5e5e; } /* Information */
+ code span.kw { color: #003b4f; } /* Keyword */
+ code span.op { color: #5e5e5e; } /* Operator */
+ code span.ot { color: #003b4f; } /* Other */
+ code span.pp { color: #ad0000; } /* Preprocessor */
+ code span.sc { color: #5e5e5e; } /* SpecialChar */
+ code span.ss { color: #20794d; } /* SpecialString */
+ code span.st { color: #20794d; } /* String */
+ code span.va { color: #111111; } /* Variable */
+ code span.vs { color: #20794d; } /* VerbatimString */
+ code span.wa { color: #5e5e5e; font-style: italic; } /* Warning */
/* CSS for citations */
div.csl-bib-body { }
div.csl-entry {
@@ -50,6 +115,22 @@
margin-left: 2em;
} </style>
<link rel="stylesheet" href="04_data_analysis_files/libs/revealjs/dist/theme/quarto.css">
+ <script>window.backupDefine = window.define; window.define = undefined;</script><script src="https://cdn.jsdelivr.net/npm/katex@0.15.1/dist/katex.min.js"></script>
+ <script>document.addEventListener("DOMContentLoaded", function () {
+ var mathElements = document.getElementsByClassName("math");
+ var macros = [];
+ for (var i = 0; i < mathElements.length; i++) {
+ var texText = mathElements[i].firstChild;
+ if (mathElements[i].tagName == "SPAN") {
+ katex.render(texText.data, mathElements[i], {
+ displayMode: mathElements[i].classList.contains('display'),
+ throwOnError: false,
+ macros: macros,
+ fleqn: false
+ });
+}}});
+ </script>
+ <script>window.define = window.backupDefine; window.backupDefine = undefined;</script><link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/katex@0.15.1/dist/katex.min.css">
<link href="04_data_analysis_files/libs/revealjs/plugin/quarto-line-highlight/line-highlight.css" rel="stylesheet">
<link href="04_data_analysis_files/libs/revealjs/plugin/reveal-menu/menu.css" rel="stylesheet">
<link href="04_data_analysis_files/libs/revealjs/plugin/reveal-menu/quarto-menu.css" rel="stylesheet">
@@ -367,9 +448,10 @@ Prof. Dr. Michael Bücker
<h2 id="toc-title">Table of contents</h2>
<ul>
<li><a href="#/analytics-methods" id="/toc-analytics-methods"><span class="header-section-number">5.1</span> Analytics methods</a></li>
-<li><a href="#/key-figures" id="/toc-key-figures"><span class="header-section-number">5.2</span> Key figures</a></li>
-<li><a href="#/best-practices" id="/toc-best-practices"><span class="header-section-number">5.3</span> Best practices</a></li>
-<li><a href="#/exercise" id="/toc-exercise"><span class="header-section-number">5.4</span> Exercise</a></li>
+<li><a href="#/explorative-data-analysis-eda" id="/toc-explorative-data-analysis-eda"><span class="header-section-number">5.2</span> Explorative Data Analysis (EDA)</a></li>
+<li><a href="#/tidy-data" id="/toc-tidy-data"><span class="header-section-number">5.3</span> Tidy data</a></li>
+<li><a href="#/variation" id="/toc-variation"><span class="header-section-number">5.4</span> Variation</a></li>
+<li><a href="#/covaration" id="/toc-covaration"><span class="header-section-number">5.5</span> Covaration</a></li>
<li><a href="#/references" id="/toc-references">References</a></li>
</ul>
</nav>
@@ -821,74 +903,616 @@ Prof. Dr. Michael Bücker
</div>
</section></section>
<section>
-<section id="key-figures" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.2">
-<h2><span class="header-section-number">5.2</span> Key figures</h2>
+<section id="explorative-data-analysis-eda" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.2">
+<h2><span class="header-section-number">5.2</span> Explorative Data Analysis (EDA)</h2>
<div class="footer">
</div>
</section>
-<section id="averages" class="slide level3" data-number="5.2.1">
-<h3><span class="header-section-number">5.2.1</span> Averages</h3>
-</section>
-<section id="variation" class="slide level3" data-number="5.2.2">
-<h3><span class="header-section-number">5.2.2</span> Variation</h3>
+<section id="introduction-to-eda" class="slide level3" data-number="5.2.1">
+<h3><span class="header-section-number">5.2.1</span> Introduction to EDA</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<h5 id="eda-is-an-iterative-process">EDA is an iterative process:</h5>
+<ol type="1">
+<li>Generate questions about your data.</li>
+<li>Search for answers by visualising, transforming, and modelling your data.</li>
+<li>Use what you learn to refine your questions and/or generate new questions.</li>
+</ol>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<h5 id="eda-is-a-state-of-mind">EDA is a state of mind:</h5>
+<ul>
+<li>EDA is not a formal process with a strict set of rules</li>
+<li>During the initial phases of EDA you should feel free to investigate every idea that occurs to you</li>
+<li>Some of these ideas will pan out, and some will be dead ends</li>
+<li>As your exploration continues, you will home in on a few particularly productive areas that you’ll eventually write up and communicate to others</li>
+</ul>
+</div>
+</div>
</section>
-<section id="ratios" class="slide level3" data-number="5.2.3">
-<h3><span class="header-section-number">5.2.3</span> Ratios</h3>
+<section id="definitions" class="slide level3" data-number="5.2.2">
+<h3><span class="header-section-number">5.2.2</span> Definitions</h3>
+<ul>
+<li><p>A <strong>variable</strong> is a quantity, quality, or property that you can measure.</p></li>
+<li><p>A <strong>value</strong> is the state of a variable when you measure it. The value of a variable may change from measurement to measurement.</p></li>
+<li><p>An <strong>observation</strong> is a set of measurements made under similar conditions (you usually make all of the measurements in an observation at the same time and on the same object). An observation will contain several values, each associated with a different variable. I’ll sometimes refer to an observation as a data point.</p></li>
+<li><p><strong>Tabular data</strong> is a set of values, each associated with a variable and an observation. Tabular data is tidy if each value is placed in its own “cellâ€, each variable in its own column, and each observation in its own row.</p></li>
+</ul>
+</section></section>
+<section>
+<section id="tidy-data" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.3">
+<h2><span class="header-section-number">5.3</span> Tidy data</h2>
+<div class="footer">
+
+</div>
</section>
-<section id="dependenciesrelationships" class="slide level3" data-number="5.2.4">
-<h3><span class="header-section-number">5.2.4</span> Dependencies/relationships</h3>
+<section id="tidy-data-1" class="slide level3" data-number="5.3.1">
+<h3><span class="header-section-number">5.3.1</span> Tidy data</h3>
+<p>Starting point for any data analysis should be a tidy dataset. You can represent the same underlying data in multiple ways. There are three interrelated rules which make a dataset tidy:</p>
+<ol type="1">
+<li>Each variable must have its own column.</li>
+<li>Each observation must have its own row.</li>
+<li>Each value must have its own cell.</li>
+</ol>
+
+<img data-src="https://bookdown.org/joone/ComputationalMethods/img/7/tidy.png" class="r-stretch quarto-figure-center"><p class="caption">Figure 5.1: Following three rules makes a dataset tidy: variables are in columns, observations are in rows, and values are in cells. (<em>Source:</em> <span class="citation" data-cites="Wickham2017R">Wickham and Grolemund (<a href="#/references" role="doc-biblioref" onclick="">2017</a>)</span>)</p></section>
+<section id="making-data-tidy" class="slide level3" data-number="5.3.2">
+<h3><span class="header-section-number">5.3.2</span> Making data tidy</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<div id="fig-tidy1" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="https://d33wubrfki0l68.cloudfront.net/3aea19108d39606bbe49981acda07696c0c7fcd8/2de65/images/tidy-9.png"></p>
+<figcaption>Figure 5.2: Pivoting into a long tidy form. (<em>Source:</em> <span class="citation" data-cites="Wickham2017R">Wickham and Grolemund (<a href="#/references" role="doc-biblioref" onclick="">2017</a>)</span>)</figcaption>
+</figure>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<div id="fig-tidy2" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="https://d33wubrfki0l68.cloudfront.net/8350f0dda414629b9d6c354f87acf5c5f722be43/bcb84/images/tidy-8.png"></p>
+<figcaption>Figure 5.3: Pivoting into a wide tidy form. (<em>Source:</em> <span class="citation" data-cites="Wickham2017R">Wickham and Grolemund (<a href="#/references" role="doc-biblioref" onclick="">2017</a>)</span>)</figcaption>
+</figure>
+</div>
+</div>
+</div>
</section>
-<section id="correlation" class="slide level3" data-number="5.2.5">
-<h3><span class="header-section-number">5.2.5</span> Correlation</h3>
+<section id="describe-tables-with-pandas" class="slide level3" data-number="5.3.3">
+<h3><span class="header-section-number">5.3.3</span> Describe tables with pandas</h3>
+<div class="columns">
+<div class="column" style="width:37.5%;">
+<ul>
+<li>In order to get an overview on a table, you can use the <code>describe</code> method</li>
+<li>By default, describe computes 7 summary figures for numeric columns (mean, standard deviation, min, max and quartiles)</li>
+<li>The argument <code>include='all'</code> adds an overview on categorical variables</li>
+</ul>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:57.5%;">
+<h5 id="example-dvd-rental">Example: DVD Rental</h5>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb1"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb1-1"><a href="#cb1-1"></a><span class="co"># Import tables</span></span>
+<span id="cb1-2"><a href="#cb1-2"></a><span class="im">import</span> pandas <span class="im">as</span> pd</span>
+<span id="cb1-3"><a href="#cb1-3"></a>dvdrental <span class="op">=</span> get_all_tables(<span class="st">"dvdrental"</span>)</span>
+<span id="cb1-4"><a href="#cb1-4"></a>dvdrental.list_tables()</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output cell-output-stdout">
+<pre><code>['film', 'actor', 'address', 'category', 'city', 'country', 'customer', 'film_actor', 'film_category', 'inventory', 'language', 'payment', 'rental', 'staff', 'store']</code></pre>
+</div>
+</div>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb3"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb3-1"><a href="#cb3-1"></a><span class="co"># Describe customer table</span></span>
+<span id="cb3-2"><a href="#cb3-2"></a>dvdrental.customer.describe(include<span class="op">=</span><span class="st">'all'</span>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output cell-output-stdout">
+<pre><code> customer_id store_id ... last_update active
+count 599.000000 599.000000 ... 599 599.000000
+unique NaN NaN ... 1 NaN
+top NaN NaN ... 2013-05-26 14:49:45.738000 NaN
+freq NaN NaN ... 599 NaN
+first NaN NaN ... 2013-05-26 14:49:45.738000 NaN
+last NaN NaN ... 2013-05-26 14:49:45.738000 NaN
+mean 300.000000 1.455760 ... NaN 0.974958
+std 173.060683 0.498455 ... NaN 0.156382
+min 1.000000 1.000000 ... NaN 0.000000
+25% 150.500000 1.000000 ... NaN 1.000000
+50% 300.000000 1.000000 ... NaN 1.000000
+75% 449.500000 2.000000 ... NaN 1.000000
+max 599.000000 2.000000 ... NaN 1.000000
+
+[13 rows x 10 columns]</code></pre>
+</div>
+</div>
+</div>
+</div>
</section>
-<section id="non-linear-relationships" class="slide level3" data-number="5.2.6">
-<h3><span class="header-section-number">5.2.6</span> Non-linear relationships</h3>
+<section id="mergejoin-tables-with-pandas" class="slide level3" data-number="5.3.4">
+<h3><span class="header-section-number">5.3.4</span> Merge/join tables with pandas</h3>
+<ul>
+<li>To join two tables, the <code>merge</code> method from Python’s pandas library can be used:</li>
+<li><strong>Syntax & Parameters:</strong>
+<ul>
+<li><code>pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, ...)</code></li>
+<li><code>left</code>: First DataFrame to join.</li>
+<li><code>right</code>: Second DataFrame to join.</li>
+<li><code>how</code>: Type of merge to perform (e.g., ‘inner’, ‘outer’, ‘left’, ‘right’).</li>
+<li><code>on</code>: Column name(s) to join on. Must be found in both DataFrames.</li>
+<li><code>left_on</code>: Column(s) from the left DataFrame to use as keys.</li>
+<li><code>right_on</code>: Column(s) from the right DataFrame to use as keys.</li>
+</ul></li>
+<li><strong>Join Types:</strong>
+<ul>
+<li><code>inner</code>: Only rows with matching keys in both DataFrames are included.</li>
+<li><code>outer</code>: All rows from both DataFrames are included, with NaN for missing keys.</li>
+<li><code>left</code>: All rows from the left DataFrame are included, along with matched rows from the right DataFrame.</li>
+<li><code>right</code>: All rows from the right DataFrame are included, along with matched rows from the left DataFrame.</li>
+</ul></li>
+</ul>
</section>
-<section id="contingency" class="slide level3" data-number="5.2.7">
-<h3><span class="header-section-number">5.2.7</span> Contingency</h3>
+<section id="example-mergejoin-tables-with-pandas" class="slide level3" data-number="5.3.5">
+<h3><span class="header-section-number">5.3.5</span> Example: Merge/join tables with pandas</h3>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb5"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb5-1"><a href="#cb5-1"></a><span class="co"># Merge customer, rental and payment tables</span></span>
+<span id="cb5-2"><a href="#cb5-2"></a>df <span class="op">=</span> (</span>
+<span id="cb5-3"><a href="#cb5-3"></a>dvdrental.customer.merge(</span>
+<span id="cb5-4"><a href="#cb5-4"></a> dvdrental.rental,</span>
+<span id="cb5-5"><a href="#cb5-5"></a> on <span class="op">=</span> [<span class="st">'customer_id'</span>]</span>
+<span id="cb5-6"><a href="#cb5-6"></a>).merge(</span>
+<span id="cb5-7"><a href="#cb5-7"></a> dvdrental.payment,</span>
+<span id="cb5-8"><a href="#cb5-8"></a> on <span class="op">=</span> [<span class="st">'rental_id'</span>, <span class="st">'customer_id'</span>]</span>
+<span id="cb5-9"><a href="#cb5-9"></a>)</span>
+<span id="cb5-10"><a href="#cb5-10"></a>)</span>
+<span id="cb5-11"><a href="#cb5-11"></a></span>
+<span id="cb5-12"><a href="#cb5-12"></a>df.describe(include<span class="op">=</span><span class="st">'all'</span>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output cell-output-stdout">
+<pre><code> customer_id store_id ... amount payment_date
+count 14592.000000 14592.000000 ... 14592.000000 14592
+unique NaN NaN ... NaN 14362
+top NaN NaN ... NaN 2007-05-14 13:44:29.996577
+freq NaN NaN ... NaN 182
+first NaN NaN ... NaN 2007-02-14 21:21:59.996577
+last NaN NaN ... NaN 2007-05-14 13:44:29.996577
+mean 297.369929 1.454701 ... 4.201143 NaN
+std 174.186580 0.497961 ... 2.368979 NaN
+min 1.000000 1.000000 ... 0.000000 NaN
+25% 145.000000 1.000000 ... 2.990000 NaN
+50% 295.000000 1.000000 ... 3.990000 NaN
+75% 449.000000 2.000000 ... 4.990000 NaN
+max 599.000000 2.000000 ... 11.990000 NaN
+
+[13 rows x 20 columns]</code></pre>
+</div>
+</div>
</section>
-<section id="difference-in-differences" class="slide level3" data-number="5.2.8">
-<h3><span class="header-section-number">5.2.8</span> Difference-in-Differences</h3>
+<section id="aggregate-tables-with-pandas" class="slide level3" data-number="5.3.6">
+<h3><span class="header-section-number">5.3.6</span> Aggregate tables with pandas</h3>
+<ul>
+<li><p>In pandas, the <code>agg</code> function is used for aggregation operations, allowing for multiple statistics to be calculated simultaneously.</p></li>
+<li><p><strong>Syntax & Parameters:</strong></p>
+<ul>
+<li><code>DataFrame.agg(func, axis=0, *args, **kwargs)</code></li>
+<li><code>func</code>: Function, string function name, list of functions, or dict of column names to functions.</li>
+<li><code>axis</code>: Axis along which the function is applied (0 for columns, 1 for rows).</li>
+</ul></li>
+<li><p><strong>Function Input Varieties:</strong></p>
+<ul>
+<li>Single function (e.g., <code>'sum'</code>)</li>
+<li>List of functions (e.g., <code>['sum', 'mean']</code>)</li>
+<li>Dictionary mapping columns to functions (e.g., <code>{'col1': 'sum', 'col2': ['mean', 'std']}</code>)</li>
+</ul></li>
+<li><p><strong>Behavior with GroupBy:</strong></p>
+<ul>
+<li>Often used in conjunction with <code>groupby</code> to perform grouped aggregations.</li>
+</ul></li>
+</ul>
</section>
-<section id="causality" class="slide level3" data-number="5.2.9">
-<h3><span class="header-section-number">5.2.9</span> Causality</h3>
+<section id="example-aggregate-tables-with-pandas" class="slide level3" data-number="5.3.7">
+<h3><span class="header-section-number">5.3.7</span> Example: Aggregate tables with pandas</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<div class="cell">
+<div class="sourceCode cell-code" id="cb7"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb7-1"><a href="#cb7-1"></a><span class="co"># Merge rental, film and actor</span></span>
+<span id="cb7-2"><a href="#cb7-2"></a>df <span class="op">=</span> (</span>
+<span id="cb7-3"><a href="#cb7-3"></a>dvdrental.rental</span>
+<span id="cb7-4"><a href="#cb7-4"></a>.merge(dvdrental.inventory, on <span class="op">=</span> [<span class="st">'inventory_id'</span>])</span>
+<span id="cb7-5"><a href="#cb7-5"></a>.merge(dvdrental.film, on <span class="op">=</span> [<span class="st">'film_id'</span>])</span>
+<span id="cb7-6"><a href="#cb7-6"></a>.merge(dvdrental.film_actor, on <span class="op">=</span> [<span class="st">'film_id'</span>])</span>
+<span id="cb7-7"><a href="#cb7-7"></a>.merge(dvdrental.actor, on <span class="op">=</span> [<span class="st">'actor_id'</span>])</span>
+<span id="cb7-8"><a href="#cb7-8"></a>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<div class="cell">
+<div class="sourceCode cell-code" id="cb8"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb8-1"><a href="#cb8-1"></a><span class="co"># Count rentals per actor</span></span>
+<span id="cb8-2"><a href="#cb8-2"></a>(</span>
+<span id="cb8-3"><a href="#cb8-3"></a> df</span>
+<span id="cb8-4"><a href="#cb8-4"></a> .groupby(by <span class="op">=</span> [<span class="st">'actor_id'</span>, <span class="st">'last_name'</span>, <span class="st">'first_name'</span>], </span>
+<span id="cb8-5"><a href="#cb8-5"></a> as_index <span class="op">=</span> <span class="va">False</span>)</span>
+<span id="cb8-6"><a href="#cb8-6"></a> .agg(count_rentals<span class="op">=</span>(<span class="st">'rental_id'</span>, <span class="st">'count'</span>))</span>
+<span id="cb8-7"><a href="#cb8-7"></a> .sort_values(by <span class="op">=</span> <span class="st">'count_rentals'</span>, ascending<span class="op">=</span><span class="va">False</span>)</span>
+<span id="cb8-8"><a href="#cb8-8"></a>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output cell-output-stdout">
+<pre><code> actor_id last_name first_name count_rentals
+106 107 Degeneres Gina 753
+180 181 Carrey Matthew 678
+197 198 Keitel Mary 674
+143 144 Witherspoon Angela 654
+101 102 Torn Walter 640
+.. ... ... ... ...
+34 35 Dean Judy 255
+198 199 Fawcett Julia 255
+30 31 Sobieski Sissy 235
+185 186 Zellweger Julia 221
+147 148 Dee Emily 216
+
+[200 rows x 4 columns]</code></pre>
+</div>
+</div>
+</div>
+</div>
</section></section>
<section>
-<section id="best-practices" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.3">
-<h2><span class="header-section-number">5.3</span> Best practices</h2>
+<section id="variation" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.4">
+<h2><span class="header-section-number">5.4</span> Variation</h2>
<div class="footer">
</div>
</section>
-<section id="definition" class="slide level3" data-number="5.3.1">
-<h3><span class="header-section-number">5.3.1</span> Definition</h3>
+<section id="variation-1" class="slide level3" data-number="5.4.1">
+<h3><span class="header-section-number">5.4.1</span> Variation</h3>
+<ul>
+<li><strong>Variation Definition:</strong> Tendency of variable values to change with each measurement.</li>
+<li><strong>Continuous Variables:</strong> Each measurement likely yields slightly different results.</li>
+<li><strong>Constant Quantities:</strong> Even with constants like the speed of light, measurements vary due to errors.</li>
+<li><strong>Categorical Variables Variation:</strong>
+<ul>
+<li>Different subjects, e.g., various people’s eye colors.</li>
+<li>Different times, e.g., an electron’s energy levels at varied moments.</li>
+</ul></li>
+<li><strong>Pattern of Variation:</strong> Each variable has a unique pattern that can provide insightful information.</li>
+<li><strong>Understanding Patterns:</strong> Visualizing a variable’s distribution helps understand its variation pattern.</li>
+</ul>
+</section>
+<section id="histograms" class="slide level3" data-number="5.4.2">
+<h3><span class="header-section-number">5.4.2</span> Histograms</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<ul>
+<li>A <strong>histogram</strong> visualizes the distribution of continuous variables</li>
+<li>A bar for each bin represents the frequency of observations in this bin</li>
+<li>Bins can be specified in different variants (e.g. same width vs. varying width)</li>
+</ul>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb10"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb10-1"><a href="#cb10-1"></a><span class="co"># Compute revenue per customer</span></span>
+<span id="cb10-2"><a href="#cb10-2"></a>df <span class="op">=</span> (</span>
+<span id="cb10-3"><a href="#cb10-3"></a>dvdrental.customer</span>
+<span id="cb10-4"><a href="#cb10-4"></a>.merge(dvdrental.rental, on <span class="op">=</span> [<span class="st">'customer_id'</span>])</span>
+<span id="cb10-5"><a href="#cb10-5"></a>.merge(dvdrental.payment, on <span class="op">=</span> [<span class="st">'rental_id'</span>, <span class="st">'customer_id'</span>])</span>
+<span id="cb10-6"><a href="#cb10-6"></a>.groupby(<span class="st">'customer_id'</span>)</span>
+<span id="cb10-7"><a href="#cb10-7"></a>.agg(revenue<span class="op">=</span>(<span class="st">'amount'</span>, <span class="st">'sum'</span>))</span>
+<span id="cb10-8"><a href="#cb10-8"></a>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<p>The <code>matplotlib</code> library offers a function <code>hist</code> to draw histograms:</p>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb11"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb11-1"><a href="#cb11-1"></a><span class="im">import</span> matplotlib.pyplot <span class="im">as</span> plt</span>
+<span id="cb11-2"><a href="#cb11-2"></a>plt.hist(df[<span class="st">'revenue'</span>], bins <span class="op">=</span> <span class="dv">10</span>)</span>
+<span id="cb11-3"><a href="#cb11-3"></a>plt.show()</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output-display">
+<div id="fig-hist" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="04_data_analysis_files/figure-revealjs/fig-hist-1.png" width="614"></p>
+<figcaption>Figure 5.4: Histogram of revenues per cusotmer in the DVD Rental data base</figcaption>
+</figure>
+</div>
+</div>
+</div>
+</div>
+</div>
+</section>
+<section id="bar-plots" class="slide level3" data-number="5.4.3">
+<h3><span class="header-section-number">5.4.3</span> Bar plots</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<ul>
+<li>In a <em>bar plot</em>, the height of a bar represents the frequency of values of a categorical variable</li>
+<li>Bars can show absolute or relative frequencies</li>
+</ul>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb12"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb12-1"><a href="#cb12-1"></a><span class="co"># Compute rentals per staff member</span></span>
+<span id="cb12-2"><a href="#cb12-2"></a>df <span class="op">=</span> (</span>
+<span id="cb12-3"><a href="#cb12-3"></a>dvdrental.customer</span>
+<span id="cb12-4"><a href="#cb12-4"></a>.merge(dvdrental.rental, on <span class="op">=</span> [<span class="st">'customer_id'</span>], </span>
+<span id="cb12-5"><a href="#cb12-5"></a> suffixes <span class="op">=</span> (<span class="st">'_customer'</span>, <span class="st">'_rental'</span>))</span>
+<span id="cb12-6"><a href="#cb12-6"></a>.merge(dvdrental.staff, on <span class="op">=</span> [<span class="st">'staff_id'</span>],</span>
+<span id="cb12-7"><a href="#cb12-7"></a> suffixes <span class="op">=</span> (<span class="st">'_customer'</span>, <span class="st">'_staff'</span>))</span>
+<span id="cb12-8"><a href="#cb12-8"></a>.groupby([<span class="st">'staff_id'</span>, <span class="st">'first_name_staff'</span>, </span>
+<span id="cb12-9"><a href="#cb12-9"></a> <span class="st">'last_name_staff'</span>, <span class="st">'email_staff'</span>], </span>
+<span id="cb12-10"><a href="#cb12-10"></a> as_index<span class="op">=</span><span class="va">False</span>)</span>
+<span id="cb12-11"><a href="#cb12-11"></a>.agg(rentals_count<span class="op">=</span>(<span class="st">'rental_id'</span>, <span class="st">'count'</span>))</span>
+<span id="cb12-12"><a href="#cb12-12"></a>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<p>The <code>matplotlib</code> library offers a function <code>bar</code> to draw histograms:</p>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb13"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb13-1"><a href="#cb13-1"></a>plt.bar(df[<span class="st">'first_name_staff'</span>], df[<span class="st">'rentals_count'</span>])</span>
+<span id="cb13-2"><a href="#cb13-2"></a>plt.show()</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output-display">
+<div id="fig-bar" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="04_data_analysis_files/figure-revealjs/fig-bar-3.png" width="960"></p>
+<figcaption>Figure 5.5: Barplot of count of rentals per staff member in the DVD Rental data base</figcaption>
+</figure>
+</div>
+</div>
+</div>
+</div>
+</div>
+</section>
+<section id="analyzing-variationdistributions" class="slide level3" data-number="5.4.4">
+<h3><span class="header-section-number">5.4.4</span> Analyzing variation/distributions</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<h5 id="questions-to-ask">Questions to ask:</h5>
+<ol type="1">
+<li>Which values are the most common? Why?</li>
+<li>Which values are rare? Why? Does that match your expectations?</li>
+<li>Can you see any unusual patterns? What might explain them?</li>
+</ol>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<h5 id="kpis-describing-the-distribution">KPIs describing the distribution:</h5>
+<ul>
+<li>Frequencies (absolute, relative)</li>
+<li>Average</li>
+<li>Standard Deviation, Variance, Median Absolute Deviation</li>
+<li>Skewness, Kurtosis</li>
+<li>Outliers</li>
+</ul>
+</div>
+</div>
</section></section>
<section>
-<section id="exercise" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.4">
-<h2><span class="header-section-number">5.4</span> Exercise</h2>
+<section id="covaration" class="title-slide slide level2 center" data-background-color="#0014a0" data-number="5.5">
+<h2><span class="header-section-number">5.5</span> Covaration</h2>
+
+</section>
+<section id="covariation" class="slide level3" data-number="5.5.1">
+<h3><span class="header-section-number">5.5.1</span> Covariation</h3>
+<ul>
+<li><strong>Variation:</strong> describes the behavior within a variable</li>
+<li><strong>Covariation:</strong> describes the behavior between variables</li>
+<li>Covariation is the tendency for the values of two or more variables to vary together in a related way</li>
+<li>The best way to spot covariation is to visualise the relationship between two or more variables</li>
+<li>How you do that should again depend on the <strong>type</strong> of variables involved.</li>
+</ul>
+</section>
+<section id="covariation-of-a-cagtegorical-and-a-continuous-variable-12" class="slide level3" data-number="5.5.2">
+<h3><span class="header-section-number">5.5.2</span> Covariation of a cagtegorical and a continuous variable (1/2)</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<ul>
+<li>A <em>bar plot</em> can be used to compare aggregated values of a numeric values across categories from another variable</li>
+<li>Aggregations can be counts, sums, …</li>
+</ul>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb14"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb14-1"><a href="#cb14-1"></a><span class="co"># Compute rentals per staff member</span></span>
+<span id="cb14-2"><a href="#cb14-2"></a>df <span class="op">=</span> (</span>
+<span id="cb14-3"><a href="#cb14-3"></a>dvdrental.customer</span>
+<span id="cb14-4"><a href="#cb14-4"></a>.merge(dvdrental.rental, on <span class="op">=</span> [<span class="st">'customer_id'</span>])</span>
+<span id="cb14-5"><a href="#cb14-5"></a>.merge(dvdrental.payment, on <span class="op">=</span> [<span class="st">'customer_id'</span>,<span class="st">'rental_id'</span>, <span class="st">'staff_id'</span>])</span>
+<span id="cb14-6"><a href="#cb14-6"></a>.merge(dvdrental.staff, on <span class="op">=</span> [<span class="st">'staff_id'</span>], suffixes <span class="op">=</span> (<span class="st">'_customer'</span>,<span class="st">'_staff'</span>))</span>
+<span id="cb14-7"><a href="#cb14-7"></a>.groupby([<span class="st">'staff_id'</span>, <span class="st">'first_name_staff'</span>, </span>
+<span id="cb14-8"><a href="#cb14-8"></a> <span class="st">'last_name_staff'</span>, <span class="st">'email_staff'</span>], </span>
+<span id="cb14-9"><a href="#cb14-9"></a> as_index<span class="op">=</span><span class="va">False</span>)</span>
+<span id="cb14-10"><a href="#cb14-10"></a>.agg(revenue<span class="op">=</span>(<span class="st">'amount'</span>, <span class="st">'sum'</span>))</span>
+<span id="cb14-11"><a href="#cb14-11"></a>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<div class="cell">
+<div class="sourceCode cell-code" id="cb15"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb15-1"><a href="#cb15-1"></a>plt.bar(df[<span class="st">'first_name_staff'</span>], df[<span class="st">'revenue'</span>])</span>
+<span id="cb15-2"><a href="#cb15-2"></a>plt.show()</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output-display">
+<div id="fig-covarbars" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="04_data_analysis_files/figure-revealjs/fig-covarbars-5.png" width="960"></p>
+<figcaption>Figure 5.6: Barplot of count of rentals per staff member in the DVD Rental data base</figcaption>
+</figure>
+</div>
+</div>
+</div>
+</div>
+</div>
+</section>
+<section id="covariation-of-a-cagtegorical-and-a-continuous-variable-22" class="slide level3" data-number="5.5.3">
+<h3><span class="header-section-number">5.5.3</span> Covariation of a cagtegorical and a continuous variable (2/2)</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<ul>
+<li>Using <strong>boxplots</strong>, the entire distribution of a continuous variable can be compared across categories of another variable</li>
+</ul>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb16"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb16-1"><a href="#cb16-1"></a><span class="co"># Merge tables for revenues</span></span>
+<span id="cb16-2"><a href="#cb16-2"></a>df <span class="op">=</span> (</span>
+<span id="cb16-3"><a href="#cb16-3"></a>dvdrental.customer</span>
+<span id="cb16-4"><a href="#cb16-4"></a>.merge(dvdrental.rental, on <span class="op">=</span> [<span class="st">'customer_id'</span>], </span>
+<span id="cb16-5"><a href="#cb16-5"></a> suffixes <span class="op">=</span> (<span class="st">'_customer'</span>, <span class="st">'_rental'</span>))</span>
+<span id="cb16-6"><a href="#cb16-6"></a>.merge(dvdrental.payment, on <span class="op">=</span> [<span class="st">'customer_id'</span>, </span>
+<span id="cb16-7"><a href="#cb16-7"></a> <span class="st">'rental_id'</span>, </span>
+<span id="cb16-8"><a href="#cb16-8"></a> <span class="st">'staff_id'</span>], </span>
+<span id="cb16-9"><a href="#cb16-9"></a> suffixes <span class="op">=</span> (<span class="st">'_customer'</span>, <span class="st">'_rental'</span>))</span>
+<span id="cb16-10"><a href="#cb16-10"></a>.merge(dvdrental.staff, on <span class="op">=</span> [<span class="st">'staff_id'</span>],</span>
+<span id="cb16-11"><a href="#cb16-11"></a> suffixes <span class="op">=</span> (<span class="st">'_customer'</span>, <span class="st">'_staff'</span>)) </span>
+<span id="cb16-12"><a href="#cb16-12"></a>)[[<span class="st">'first_name_staff'</span>, <span class="st">'amount'</span>]]</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<p>The <code>seaborn</code> library offers a function <code>sns.boxplot</code> to easily draw multiple boxplots for comparison:</p>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb17"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb17-1"><a href="#cb17-1"></a><span class="im">import</span> seaborn <span class="im">as</span> sns</span>
+<span id="cb17-2"><a href="#cb17-2"></a>sns.boxplot(x <span class="op">=</span> <span class="st">'first_name_staff'</span>, y <span class="op">=</span> <span class="st">'amount'</span>, data <span class="op">=</span> df)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output-display">
+<div id="fig-boxs" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="04_data_analysis_files/figure-revealjs/fig-boxs-7.png" width="960"></p>
+<figcaption>Figure 5.7: Boxplots of revenues per rental separately by staff members</figcaption>
+</figure>
+</div>
+</div>
+</div>
+</div>
+</div>
+</section>
+<section id="covariation-of-two-cagtegorical-variables" class="slide level3" data-number="5.5.4">
+<h3><span class="header-section-number">5.5.4</span> Covariation of two cagtegorical variables</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<p>Create a table to identify the number of rentals per film category and country:</p>
+<div class="cell">
+<div class="cell-output cell-output-stdout">
+<pre><code> country name count
+0 Australia Action 516
+1 Australia Animation 598
+2 Australia Children 492
+3 Australia Classics 492
+4 Australia Comedy 439
+5 Australia Documentary 600
+6 Australia Drama 484
+7 Australia Family 539
+8 Australia Foreign 509
+9 Australia Games 514
+10 Australia Horror 460
+11 Australia Music 394
+12 Australia New 438
+13 Australia Sci-Fi 580
+14 Australia Sports 624
+15 Australia Travel 442
+16 Canada Action 596
+17 Canada Animation 568
+18 Canada Children 453
+19 Canada Classics 447
+20 Canada Comedy 502
+21 Canada Documentary 450
+22 Canada Drama 576
+23 Canada Family 557
+24 Canada Foreign 524
+25 Canada Games 455
+26 Canada Horror 386
+27 Canada Music 436
+28 Canada New 502
+29 Canada Sci-Fi 521
+30 Canada Sports 555
+31 Canada Travel 395</code></pre>
+</div>
+</div>
+</div><div class="column" style="width:5%;">
+</div><div class="column" style="width:47.5%;">
+<p>The <code>seaborn</code> library offers a function <code>heatmap</code> to create heatmaps:</p>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb19"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb19-1"><a href="#cb19-1"></a>df_pivot <span class="op">=</span> df.pivot(index<span class="op">=</span><span class="st">"name"</span>, columns<span class="op">=</span><span class="st">"country"</span>, values<span class="op">=</span><span class="st">"count"</span>)</span>
+<span id="cb19-2"><a href="#cb19-2"></a>sns.heatmap(df_pivot)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output-display">
+<div id="fig-heatmap" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="04_data_analysis_files/figure-revealjs/fig-heatmap-9.png" width="960"></p>
+<figcaption>Figure 5.8: Heatmap for rentals across film categories and countries</figcaption>
+</figure>
+</div>
+</div>
+</div>
+</div>
+</div>
</section>
-<section id="exercise-1" class="slide level3" data-number="5.4.1">
-<h3><span class="header-section-number">5.4.1</span> Exercise</h3>
-<div class="callout callout-caution callout-titled callout-style-default">
-<div class="callout-body">
-<div class="callout-title">
-<div class="callout-icon-container">
-<i class="callout-icon"></i>
+<section id="covariation-of-two-continuous-variables" class="slide level3" data-number="5.5.5">
+<h3><span class="header-section-number">5.5.5</span> Covariation of two continuous variables</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<p>Create a table with duration and amount paid</p>
+<div class="cell">
+<div class="cell-output cell-output-stdout">
+<pre><code> rental_id duration amount
+0 1158 3.865278 2.99
+1 1164 7.964583 0.99
+2 1165 9.110417 3.99
+3 1166 8.227778 4.99
+4 1169 2.100000 2.99
+... ... ... ...
+7263 16039 5.054861 2.99
+7264 16040 4.074306 11.99
+7265 16042 8.857639 2.99
+7266 16045 9.169444 0.99
+7267 16049 2.240278 3.99
+
+[7268 rows x 3 columns]</code></pre>
+</div>
+</div>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<p>The <code>pandas</code> library offers a method <code>plot.scatter</code> to create scatterplots:</p>
+<div class="cell">
+<div class="sourceCode cell-code" id="cb21"><pre class="sourceCode numberSource python number-lines code-with-copy"><code class="sourceCode python"><span id="cb21-1"><a href="#cb21-1"></a>df.plot.scatter(x <span class="op">=</span> <span class="st">'duration'</span>, y <span class="op">=</span> <span class="st">'amount'</span>)</span></code><button title="Copy to Clipboard" class="code-copy-button"><i class="bi"></i></button></pre></div>
+<div class="cell-output-display">
+<div id="fig-scatter" class="quarto-figure quarto-figure-center">
+<figure>
+<p><img data-src="04_data_analysis_files/figure-revealjs/fig-scatter-11.png" width="960"></p>
+<figcaption>Figure 5.9: Scatterplot for rental duration and amount paid</figcaption>
+</figure>
</div>
-<p><strong>Exercise</strong></p>
</div>
-<div class="callout-content">
-<p>Please analyze the following use case</p>
</div>
</div>
+</div>
+</section>
+<section id="analyzing-covariationrelationshipsdependencies" class="slide level3" data-number="5.5.6">
+<h3><span class="header-section-number">5.5.6</span> Analyzing covariation/relationships/dependencies</h3>
+<div class="columns">
+<div class="column" style="width:47.5%;">
+<h5 id="questions-to-ask-1">Questions to ask:</h5>
+<ol type="1">
+<li>Which variables show common patterns? Are they reasonable/explainable?</li>
+<li>What form does the relationship have: is it linear, non-linear?</li>
+</ol>
+</div><div class="column" style="width:5%;">
+
+</div><div class="column" style="width:47.5%;">
+<h5 id="kpis-describing-the-distribution-1">KPIs describing the distribution:</h5>
+<ul>
+<li>Correlaion (Pearson, Spearman, Kendall)</li>
+<li>Contingency (<span class="math inline">\chi^2</span>, Cramérs <span class="math inline">V</span>)</li>
+<li>…</li>
+</ul>
+</div>
+</div>
+</section>
+<section id="looking-back-data-preparation" class="slide level3" data-number="5.5.7">
+<h3><span class="header-section-number">5.5.7</span> Looking back: Data preparation</h3>
+
+<img data-src="img/featureengineering2.png" class="r-stretch quarto-figure-center"><p class="caption">Figure 5.10: Visualization of the data preparation tasks</p></section>
+<section id="feature-engineering" class="slide level3" data-number="5.5.8">
+<h3><span class="header-section-number">5.5.8</span> Feature engineering</h3>
+
+<img data-src="img/featureengineering.png" class="r-stretch quarto-figure-center"><p class="caption">Figure 5.11: Visualization of feature engineering tasks</p><div class="footer">
+
</div>
</section></section>
<section id="references" class="title-slide slide level2 unnumbered scrollable smaller">
<h2>References</h2>
-<div id="refs" role="list">
-
+<div id="refs" class="references csl-bib-body hanging-indent" role="list">
+<div id="ref-Wickham2017R" class="csl-entry" role="listitem">
+Wickham, Hadley, and Garrett Grolemund. 2017. <em>R for Data Science: Import, Tidy, Transform, Visualize, and Model Data</em>. 1st ed. O’Reilly Media. <a href="http://r4ds.had.co.nz/">http://r4ds.had.co.nz/</a>.
+</div>
</div>
<img src="img/logo.png" class="slide-logo r-stretch"><div class="footer footer-default">
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-bar-3.png b/output/04_data_analysis_files/figure-revealjs/fig-bar-3.png
new file mode 100644
index 0000000000000000000000000000000000000000..74f428ba1b3983c4854d3115a16ddb773c1d92b2
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-bar-3.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-bar-5.png b/output/04_data_analysis_files/figure-revealjs/fig-bar-5.png
new file mode 100644
index 0000000000000000000000000000000000000000..74f428ba1b3983c4854d3115a16ddb773c1d92b2
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-bar-5.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-boxs-3.png b/output/04_data_analysis_files/figure-revealjs/fig-boxs-3.png
new file mode 100644
index 0000000000000000000000000000000000000000..4b8fde2d151be5b30e4d2803a304ba0def0d2914
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-boxs-3.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-boxs-7.png b/output/04_data_analysis_files/figure-revealjs/fig-boxs-7.png
new file mode 100644
index 0000000000000000000000000000000000000000..4b8fde2d151be5b30e4d2803a304ba0def0d2914
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-boxs-7.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-covarbars-5.png b/output/04_data_analysis_files/figure-revealjs/fig-covarbars-5.png
new file mode 100644
index 0000000000000000000000000000000000000000..eaecd87b18e6a6b62d1cac6bb2232b569511b642
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-covarbars-5.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-heatmap-9.png b/output/04_data_analysis_files/figure-revealjs/fig-heatmap-9.png
new file mode 100644
index 0000000000000000000000000000000000000000..23fbfa8a33aa00811331d35f804a2526905f7aa3
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-heatmap-9.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-hist-1.png b/output/04_data_analysis_files/figure-revealjs/fig-hist-1.png
new file mode 100644
index 0000000000000000000000000000000000000000..4d396c98a31acdb4bddf2cc161a54648d46feacb
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-hist-1.png differ
diff --git a/output/04_data_analysis_files/figure-revealjs/fig-scatter-11.png b/output/04_data_analysis_files/figure-revealjs/fig-scatter-11.png
new file mode 100644
index 0000000000000000000000000000000000000000..665e4c669e8fe688b34f92199a9e3e5b08d52997
Binary files /dev/null and b/output/04_data_analysis_files/figure-revealjs/fig-scatter-11.png differ
diff --git a/output/img/featureengineering2.png b/output/img/featureengineering2.png
new file mode 100644
index 0000000000000000000000000000000000000000..dddc6709391df37c76c8dac78fc9ff0e0db544cc
Binary files /dev/null and b/output/img/featureengineering2.png differ
diff --git a/references.bib b/references.bib
index e9b0e6b2ee173c1c5e03dc245a7d11ce63da2707..4e88ee0c6f1caad80d6811be3f3778ee807f8de3 100644
--- a/references.bib
+++ b/references.bib
@@ -91,4 +91,15 @@
year = 2016
}
+@book{Wickham2017R,
+ author = {Wickham, Hadley and Grolemund, Garrett},
+ edition = 1,
+ publisher = {O'Reilly Media},
+ title = {R for Data Science: Import, Tidy, Transform, Visualize, and Model Data},
+ url = {http://r4ds.had.co.nz/},
+ year = 2017
+}
+
+
+